Дори на пръв поглед неизвестните кодъри оставят своите “пръстови отпечатъци”, които могат да бъдат идентифицирани чрез машинно обучение. Ако обаче програмистът търси анонимност, той лесно може да заобиколи съществуващите системи за идентификация и дори да се представи за друг.
Специалистите в сферата на статистическия анализ на езиковия стил (стилометрия) отдавна знаят, че писането е уникален, индивидуализиран процес. Речникът, който използва даден човек, характерния за него синтаксис и граматически решения служат като оригинален подпис за всеки един от нас. Автоматизираните инструменти вече могат да идентифицират кой е авторът на определено съобщение във форум, стига да разполагат с достатъчно данни за анализ. Новите изследвания показват, че стилометрията може да се приложи и към изкуствени езикови модели, като например програмен код, тъй като дивелъпърите също оставят “пръстови отпечатъци”.
Рейчъл Грийнщадт от Университета Дрексел и Айлийн Каликан от университета “Джордж Вашингтон” установяват, че кодът, подобно на други форми на стилистичен израз, няма как да остане анонимен. На конференцията DefCon, учените ще представят серия от проучвания, които са провели, използвайки техники за машинно обучение, за да разбият анонимността на автори на пробни кодове. Част от работата е финансирана и проведена в сътрудничество с лабораторията за изследване на армията на САЩ.
Резултатите могат да бъдат полезни при наличие на спор за плагиатството, но също така могат да имат и някои последици за поверителността на хиляди дивелъпъри, работещи с отворен код.
Основният метод на компютърната стилоскопия е търсенето на характерни пробни кодове, според които е възможно да се “изчисли” авторът (има около 50 такива проби). На тяхна основа се формира “абстрактно синтактично дърво”, което отразява основната структура на кода и дава възможност за идентифициране на автора.
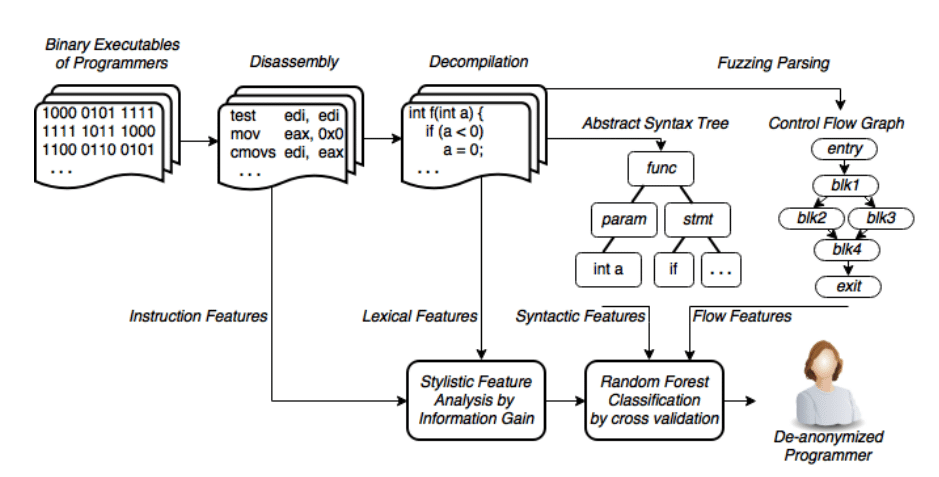
Принцип за разбиране на анонимността на програмиста
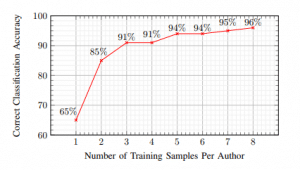
За да успеете да обучите машината, ви е нужна база данни за сравнение. За един от експериментите авторите са използвали примерни кодове от годишния конкурс на Google Code Jam. Алгоритъмът за машинно обучение идентифицира правилно група от 100 програмиста в 96% от случаите, използвайки осем проби от кодове за всеки от тях. Дори когато размерът на базата данни бъде разширен до 600 програмисти, алгоритъмът достига точност от 83%.
 Не всичко, обаче, изглежда толкова тъжно за ИТ специалистите. В отговор на развитието на идентификационния механизъм изследователският екип от университета във Вашингтон откри, че програмисти и без специално обучение могат да създадат код с намерение да мамят алгоритъма и да се представят за друг автор.
Не всичко, обаче, изглежда толкова тъжно за ИТ специалистите. В отговор на развитието на идентификационния механизъм изследователският екип от университета във Вашингтон откри, че програмисти и без специално обучение могат да създадат код с намерение да мамят алгоритъма и да се представят за друг автор.
Източник: portaltele