Кристиян Боянов е родом от Монтана и е завършил ПМГ “Св. Климент Охридски”, където се разпалва неговият интерес към софтуерното инженерство. Кристиян е тромпетист и програмист, който решава да разработи интересен проект за композиране на българска народна музика. Научете за работата по изкуствения интелект и как можете да помогнете в развитието на идеята.
Кристиян Боянов е родом от Монтана и е завършил ПМГ “Св. Климент Охридски”, където се разпалва неговият интерес към софтуерното инженерство. Кристиян е тромпетист и програмист, който решава да разработи интересен проект за композиране на българска народна музика. Научете за работата по изкуствения интелект и как можете да помогнете в развитието на идеята.
Разкажи ни как се появи у теб интереса към изкуствения интелект?
Проявявам интерес към изкуствения интелект от много време. През 2014г. разработих проект, който представляваше резюмиране на текст и изготвяне на презентация по него. С него спечелих Националната олимпиада по ИТ и получих „Награда Джон Атанасов за ученици“ на Президента на Република България. От тогава не съм спирал да чета и да разработвам свои проекти.
Какъв е поводът за разработването на проекта?
Аз съм последен семестър в Софийски университет “Св. Климент Охридски”, специалност “Софтуерно инженерство”. Реших да се включа в избираемата дисциплина “Изкуствен интелект”, за която всички студенти трябваше да изработят финален проект, за да бъдат оценени. Замислих се как мога да използвам едно от хобитата си за целта. Аз съм тромпетист още от училище, където бях музикант в училищния оркестър. Реших да използвам това свое умение и да го приложа в своя проект, за да изготвя нещо, което да бъде интересно за мен и за околните. Приех целта си за предизвикателство, тъй като тя не беше твърде лесна за изпълнение, а и така тествах самия себе си. Това беше мотивацията да изготвя този проект .
Защо избра да създадеш композитор на български народни песни?
Изборът ми на тематиката с фолклор мотиви допълнително внася трудност в реализация на проекта, защото такива песни са трудни за изпълнение дори от известни изпълнители. Идеята ми бе изпитание и към самите възможности на изкуствения интелект. Вярвам, че самият проект е възможно да тласне AI напред, особено ако аз самия открия някакво развитие в тази област.
Такива приложения вече съществуват и те са свързани с изкуството – примери за това са други скриптове, които генерират поезия, такива, които генерират импресии, невронни мрежи, генериращи картини. Дори последната новост, за която се сещам е свързана с Generative Adversarial Networks, които състезаваха самите себе си как могат да създадат по-добро нещо. Те са доста напред в областта на изображенията и дори са достигнали момент, в който трудно може да се разграничи дали дадено изображение е генерирано от човек или не. Всички тези новости са доста интересни за мен и така реших да започна да работя в тази посока.
Как функционира и какви бяха основните трудности, които срещна при разработката на проекта?
Гледам на композирането на музиката като на композиране на текст, където нотите, паузите, акордите са като част от речта – думи или препинателни знаци. Поглеждайки от тази перспектива, можем да открием сходности при разработването на желаното решение. Пример е autocomplete-ът, който ни е познат в нашите телефони. Той довършва всяка мисъл, която си започнал. На същия принцип работи и моят проект, нужно е първоначално да бъдат зададени произволни ноти, които впоследствие могат да бъдат довършени до безкрайност и така абсолютно самостойно да се генерира музика.
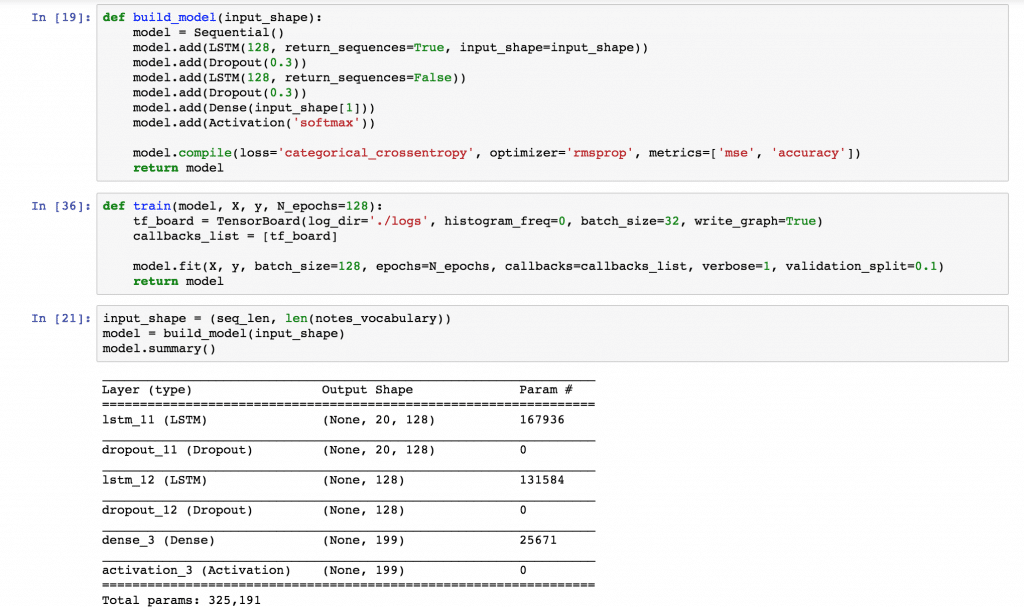
За разработката използвах невронни мрежи, по-специално LSTM (Long-short Term Memory), които са може би са доста подходящи за решаване на такъв тип проблеми, тъй като по-добре предвиждат следващите знаци и хващат контекста на случващото се на базата на предходни ноти и паузи. Те трябва да получават набор от фийчъри, отрязък от вече съществуващи песни, които аз представям по дискретен начин, тоест всяка една нота се landhost-ва и коди, за да може да бъде представена като вектор в някакво векторно пространство. След това процесът продължава на база на dataset с вече съществуващи музикални файлове. Форматът, който използвам е MIDI, тъй като позволява много лесно да се декодира и извлича нотата.
Колко време ти отне реализацията на финалния продукт?
Работих по проекта около седмица, сам, тъй като все пак това бе проект, в който трябва да приложа наученото от семестъра. Трудната част от реализацията бе да намеря dataset данни, с които да го обуча и въпреки дългото ми търсене в интернет, задачката се оказа трудна. Затова се свързах със свои колеги музиканти, които ми изпращаха MIDI файлове.
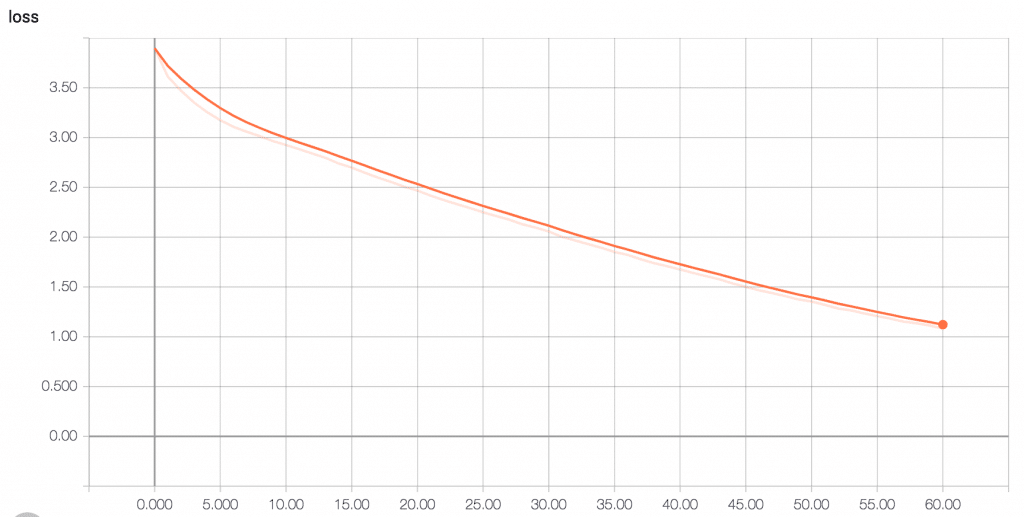
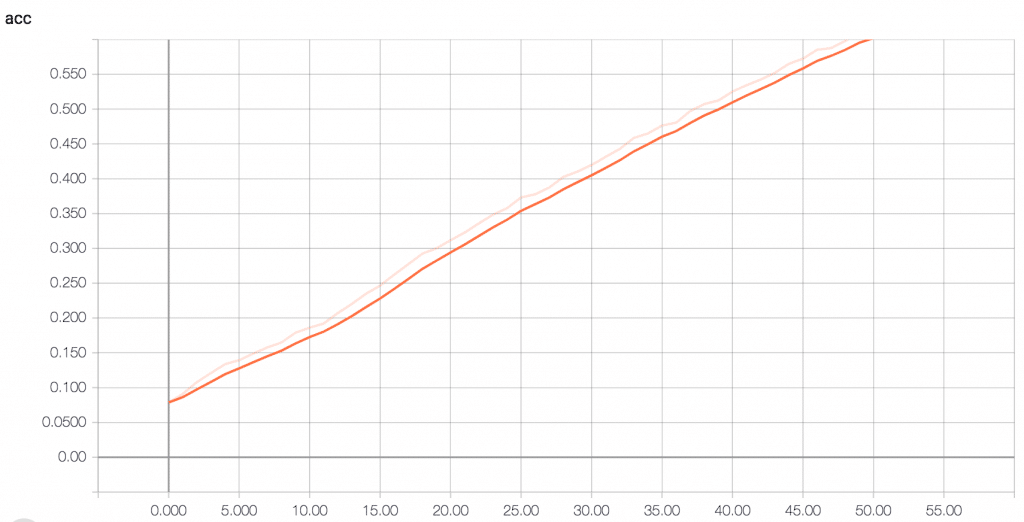
Самото обучение също бе доста трудно, за целта е нужна хубава машина с добра видеокарта, за да се натренина добре невронната мрежа. Като резултати, чисто със стойностите – “accuracy” и “loss”, получавах резултати като за overfit-ване на dataset-a, което означава, че или dataseta е малък, или че алгоритъмът ми достига едно ниво, в което научава много добре песните и започва да overfit-ва. В конкретния случай на моя проблем, това не е толкова лошо, защото започва да генерира песни, които приличат на обучените, което е и същността на самата задача. Реално когато в AI се наблюдава подобен проект, предимно се гледа да не overfit-ва и да генерализира добре.
Какви са бъдещите ти амбиции за развитие на композитора?
Специално този свой проект възнамерявам да го пусна open source, за да може хората сами да го доразвият, ако имат желание. Имам идея всички желаещи да могат да се включват с dataset с български песни и да могат да допринасят за развитието. Нямам никакви комерсиални цели. Имам други идеи, свързани с изкуствен интелект, като например разработка на text-to-speech на български. Друг мой проект е домашен асистент, подобен на Google Home и Alexa, който да помага на хора с проблеми, като дори вече разполагам с работещ прототип.
Интервюто проведе Вяра Стефчева.