На 21 юни световни експерти в програмния език С++ ще представят пред българската технологична общност новите възможности на стандарт С++26. Конференцията „C++: пътища и перспективи” (С++: Paths & Perspectives) е отворена за българските професионалисти, които искат да научат какви са промените, които ще настъпят в една от най-използваните технологии за системно програмиране.
Лектори на конференцията са членове на работната група за стандартите на С++ WG21 към Международния комитет по стандартизация ISO/IEC/JTC 1/SС 22. Те са активни участници в работните дискусии по ключови теми като сигурност (safety), отражение (reflection), контракти (contracts), подсилване (hardening).
Конференцията „C++: пътища и перспективи” ще се проведе в Гранд хотел „Милениум“ в София от 13:00 ч. на 21 юни, събота. Програмата е изцяло на английски език. Достъпът до събитието е безплатен, но се изисква предварителна регистрация, поради ограничения брой места. Организатори на срещата са Bosch Digital, Chaos Software, Man Group и NVIDIA, които обединиха сили, за да дадат възможност на българските специалисти да обменят идеи със световните експерти и да насърчат повече участници от България да бъдат активни в процесите по формиране на бъдещите стандарти на технологията.
Посетителите на конференцията ще се срещнат с Хърб Сътър (Herb Sutter), световен експерт в С++ и председател на работната група за стандартите в С++ със значим принос в развитието на модерния програмен език, Citadel Securities; Давид Вандервурде (Daveed Vandevoorde), експерт по компилатори и водещ автор на предложението за „отражение” (reflection) в C++, директор в EDG, Джошуа Берн (Joshua Berne), експерт в областта на “контракти” (contracts), Bloomberg, Гонсало Брито (Gonzalo Brito), участник в групата за преносим C++ (portable), NVIDIA, и Константин Варламов (Konstantin Varlamov), отговорник за C++ standard library, Apple.
В дискусиите на конференцията ще се включи и Петър Димов, дългогодишен делегат от името на Българския институт за стандартизация в групата за стандартите за С++. Той има съществен принос към развитието на езика, вкл. и въвеждането на механизма за т.нар. „отражения“ (reflection) в C++. Като водещ разработчик в Boost и автор на ключови библиотеки като Boost.SmartPtr и Boost.Bind, неговата работа има трайно влияние върху развитието на стандартната библиотека в С++. Модератор и инициатор на събитието е д-р Васил Василев, водещ разработчик по компилатори и консултант към Princeton University и CERN. Той е ръководител на българската делегация в ISO/IEC JTC1/SC22 и е активен участник в развитието и стандартизацията на езика C++, както и в устойчивото развитие на отворения софтуер за научни изследвания.
В панелна дискусия по време на конференцията представители на Bosch Digital, Chaos и Man Group ще демонстрират проекти, разработени от екипите им с технологията С++ и ще коментират как се създават иновации в България.
„Стандартът С++26 ще даде възможност за качествено нов начин на създаване на програми на C++ и в системното програмиране като цяло. Новият стандарт ще подобри сигурността на кода и ще добави нови функционалности, съобразени с актуалните предизвикателства в програмирането.“
коментира д-р Васил Василев.
„Имаме и повод за гордост, защото благодарение на усилията на Петър Димов българското национално представителство в работната група WG21 за С++ има съществено участие в разработването на новия механизъм за програмиране със С++ Reflection. До 2015 г. България не беше представена в стандартизацията на езиците за програмиране, докато днес националният комитет БИС/ТК 57 „Информационни и комуникационни технологии“ е активен член на ISO/IEC/JTC 1/SС 22. Чудесно е и че все повече компании участват активно с най-добрите си експерти в този процес“.
Срещата в София на 21 юни е второ издание на конференцията „C++: пътища и перспективи” след успешното първо събитие през 2023 г., което срещна българската общност със създателя на С++ Бярне Строуструп. Непосредствено преди конференцията тази година, повече от сто световни експерти по С++ ще проведат затворени работни срещи за финализирането на техническото съдържание на стандарта С++26 в София. България за втори път е домакин на работна среща на комитета и е първата държава от Югоизточна Европа, която посреща делегатите на международния съвместен технически комитет за стандартите за С++ (WG21). Първите дискусии на новия стандарт започнаха в България след финализирането на предишния стандарт С++23 през 2023 г. Партньори на срещата на WG21 в България са софтуерната компания Chaos и Българският институт по стандартизация.
Международният комитет ISO/IEC/JTC 1, към чийто подкомитет работи групата WG21, е съвместен орган към двете международни организации по стандартизация ISO (International Organization for Standardization) и IEC (International Electrotechnical Commission). Подкомитетът, който разработва стандартите за програмни езици, е SС 22 „Езици за програмиране, техните среди и системни софтуерни интерфейси”. България и българските експерти участват в работата им чрез Българския институт за стандартизация, който представлява държавата в тези органи и предоставя възможност на заинтересованите компании и експерти да се включват в стандартизационната дейност на международно ниво. Предложенията за промени обикновено изминават дълъг път на дискусии в работните групи, които могат да продължат години, и се одобряват с гласуване от членовете на комитета.
]]>Постигането на високо ниво на Software Craftsmanship е непрекъснат процес, който съпътства професионалното развитие на всеки софтуерен инженер. Това не е просто техническа компетентност, а култура на писане на чист, четим, поддържан и сигурен код. Отговорността за това е както на самите разработчици, така и на компаниите, които изграждат екипите и задават стандартите.
Подходът към имплементацията – от архитектурните решения до най-малкия детайл в кода – е показателен за професионалното ниво на един инженер. Писането на висококачествен код изисква не само опит, но и осъзнатост за дългосрочната устойчивост на системите, тяхната сигурност и възможност за скалиране.
В епизода “Майстори на Кода:: Software Craftsmanship” от поредицата The BIG Tech #BG, водещи експерти от българската технологична сцена ще дискутират:
- Кои са ключовите принципи на Software Craftsmanship в реална разработка
- Какъв е пътя за постигане на Software Craftsmanship и каква е ролята на компаниите
- Как организациите поставят фокус върху сигурността и качеството на кода
- Какви са добрите практики за избягване на често срещани грешки
- Разликите между cloud-native и on-prem решения – и как да направим правилния избор спрямо нуждите на проекта
Ако искате не просто да пишете код, а да изграждате софтуер на едно следващо ниво – с мисъл за архитектура, устойчивост и етика – този епизод е за вас. Гледайте “Майстори на Кода:: Software Craftsmanship” тук.
Поредицата “The BIG Tech #BG” е дело на екипа на DevStyleR – специализираната платформа за разработчици на софтуер, хардуер и иновации. Продукцията включва над 10 епизода, посветени на горещи теми за технологичната общност.
Сред компаниите, чийто представители може да гледате в епизода “Майстори на Кода:: Software Craftsmanship” са: Sciant (now Sirma) и “Информационно обслужване” АД
Епизодът може да гледате онлайн в канала на DevStyleR.BG в YouTube.
Гледайте и останалите епизоди от поредицата:
- Корпоративната Култура и Имидж
- Най-Желаните ИТ Позиции – част 2
- Най-Желаните ИТ Позиции – част 1
- Жените в #Tech Сферата
- ИТ Образование и Обучение – част 2
- ИТ Образование и Обучение – част 1
- ИТ Индустрията във Варна – част 2
- ИТ Индустрията във Варна – част 1
Ако желаете да станете част от участниците в проекта и да споделите мнение, може да ни пишете на [email protected]
]]>React използва процес, наречен „реконсилиране“, за да открие и приложи само най-необходимите промени, вместо да презарежда целия интерфейс. Това прави приложенията по-бързи и плавни. С този подход разработчиците могат да създават по-“отзивчиви” и ефективни уеб приложения с минимални презареждания.
Ако искате да разберете как работи Virtual DOM и защо е толкова важен за модерните уеб технологии, вижте оригиналния материал What is Virtual DOM in React.js на експерта Кристиян Велков в DevStyleR.IO.
Изображението и материалът са предоставени от Кристиян Велков
]]>В специално интервю за DevStyler Станимир разказва как се постига баланс между устойчивост и независимост при изграждане на успешни работни екипи, как се развива един стар софтуерен продукт по нов начин и защо продължава да нарича разработването на DocuWare вълнуващо толкова години по-късно.
Колко е голяма системата DocuWare понастоящем?
Интересно е как всъщност да бъде измерена големината на една такава система – защото няма смисъл да броим редове код и мегабайти. Но пък е показателно колко хора са ангажирани в изграждането на DocuWare. Докато преди 20 години системата бе разработвана от десетина специалисти в Германия и 3-4 в България, то днес по нея работят общо 130 души, от които 80 са в нашия екип.
Броят на потребителите на DocuWare нараства по подобен начин. В началото имахме десетки клиенти в Германия, а днес десетки хиляди компании по цял свят ползват продукта ежедневно.
Как се отрази развитието на DocuWare на работата ви?
Еволюцията на DocuWare беше основен двигател на промяната и при нас. Някога съществуваха т.нар. “важни клиенти” и най-важното в работата ни беше именно те да са доволни от продукта. Тогава беше напълно възможно да съществуват бъгове, които те обаче не забелязват, съответно ние нямаме обратна връзка за тях. Откакто обаче потребителите станаха хиляди, всеки проблем излиза на бял свят. Така по естествен начин изискванията за качество станаха много, много високи.
Как се справихте с организирането на работните процеси при постоянното увеличаване броя на специалистите, разработващи системата?
На практика в нашата сфера няма индустриален стандарт, защото работата по всеки софтуерен продукт е много различна. В DocuWare екипа се опитваме да следваме някои добри практики, като при това ги адаптираме спрямо нашите нужди.
Когато екипът ни беше малък, не ни бяха нужни някакви специални процеси и формализация. Впоследствие се наложи да разграничим няколко отделни екипа, да градим обща организационна структура, съответно – да въведем процеси, чрез които екипите да се синхронизират. Минахме през Waterfall модел, после през Scrum, а когато започнахме да разработваме DocuWare за Cloud, стигнахме до популярното днес DevOps.
С времето, като основна ценност при нас се наложи скалирането. Тоест да продължим да включваме все повече и повече хора, като при това и DocuWare да работи без прекъсвания, и нашата вътрешна организация да не пострада. При всяка от промените в работните процеси търсим правилния баланс между устойчивост и независимост. От една страна, искаме да имаме структура от независими екипи, които да се справят съвсем сами с едно парче от продукта. От друга страна – искаме когато в един екип е приложено едно добро решение, всички останали да започнат да го прилагат.
Освен това, навремето групирахме хората технологично – по бекенд, по фронтенд, или пък по Cloud операции. Така много добре се получаваше вътрешното разпределение на знания и споделяне на добри практики, защото хората говореха на един и същи език. Но за да постигнем модулност и независимост на екипите, решихме, че в един екип трябва да има всякакви специалисти. Така скалираме по-лесно и добавяме нови екипи, когато имаме нужда от развитие на продукта.
 DocuWare може да се похвали с вече 35 години история. Предизвикателство ли е да развиваш стара система в нови направления?
DocuWare може да се похвали с вече 35 години история. Предизвикателство ли е да развиваш стара система в нови направления?
Разбира се. Именно заради тази дълга история, има потребители, които ползват DocuWare буквално от десетилетия. Това би могло да бъде изключително ограничаващо нашата работа, тъй като всички промени, особено фундаменталните срещат сериозен отпор.
Това не действа ли малко обезсърчаващо?
Не, даже напротив. Работата по истински продукт, който всекидневно използват хиляди хора, носи огромно удовлетворение. Нашата цел не е просто да напишем хубав код, а да помогнем на някой да свърши по-добре работата си.
Освен това, в DocuWare винаги сме следили внимателно технологичните трендове и прилагали най-новите технологии. И често се е оказвало, че вземаме правилни решения. От чистата Windows платформа преминахме директно към .NET, когато тя беше още във версия 1.0. Когато пък се появи HTML 5, зарязахме десктоп приложенията и насочихме всички усилия към браузърите. Започнахме да разработваме DocuWare за Cloud още през 2010.
Правим всички тези стъпки отрано. Това е истинско предизвикателство, но пък по този начин често успяваме да изпреварим останалите технологично. Това привлича програмистите към DocuWare и прави хората в екипа доволни от работата си.
Спомена DocuWare Cloud. Какво промени разработването му за вашия екип?
Коренно се промени темпът ни на работа. Въпреки че и On-premise, и Cloud системата имат еднакви функционалности, тези два свята се развиват с различна динамика. При Cloud очакванията не са за един major release на всеки 6 месеца, а за множество по-малки и по-чести. Когато има нова On-premise версия, не всички потребители я инсталират веднага. Това ни дава възможност да разбираме за проблемите един по един. При DocuWare Cloud обаче в един и същи ден ъпдейтваме системата на няколко хиляди компании и буквално след няколко часа сe сблъскваме с проблемите на хиляди потребители. Разбира се, те трябва да бъдат разрешени изключително бързо.
Така работата по Cloud системата ни направи по-agile – планирането остава по-назад, по-важно става времето за реакция. В това ще ни помогне и предстоящото откриване в България на новия DocuWare център за технологични консултации и поддръжка на клиенти от региона на Европа, Близкия Изток и Африка. Досега центровете бяха в САЩ и Германия – работихме отлично с тях, но все пак ни бяха малко далечни. А сега ще е много по-лесно да комуникираме със съпорт екипите, да вникнем в проблемите, да се запознаем по-детайлно с работата им.
Кога DocuWare Cloud ще замени напълно On-premise?
Задаваме си този въпрос, откакто започнахме да се занимаваме с Cloud. Все още има компании, които работят на On-premise отдавна и се страхуват от промяната. Но дори в консервативен сектор като този за управление на документи, бързо стана ясно, че много хора са готови да пробват новите възможности. Още преди 2 години продажбите на On-premise и Cloud се изравниха, а в момента са около 60/40 в полза на Cloud.
От години казваме, че DocuWare е Cloud First компания, но някога ще стане и Cloud Only.
В крайна сметка, за какви програмисти е вашият екип?
Ние не сме консервативни в подбора – стремим се да има баланс между специалисти, които са напред технологично и имат богат опит, и по-младите, които са по-отворени към новото, например към DevOps тенденциите.
DocuWare eкипът е най-вече за хора, които обичат предизвикателствата и иновациите. Специалисти, които имат желание да работят по жив продукт, който се използва от все повече и повече хора. Това не е стандартно приложение, не е нов продукт, който разработваме от нула. Затова и ние не сме стандартен екип, не работим по шаблон.

Фотограф – Лилия Йотова
Бихте ли ни разказали за старта на Вашия кариерен път и за това как се запалихте по технологиите?
Връщайки се назад във времето, във вече далечната 1994 година, баща ми донесе вкъщи компютър за пръв път. Разбира се, тогава нищо не разбирах, но той се занимаваше както на работа, така и в къщи с разработката на различни програми, най-често за обществена администрация. Спомням си, че бях изключително впечатлен как чрез някакви редове текст, може да се улесни и автоматизира работата на хората. Години по-късно, записах извънкласни занимания по програмиране – тогава Pascal, а на следващ етап С и С++. Школата, която посещавах, изпращаше редовно ученици по олимпиади по програмиране – локални и национални, което спомогна за развитието на моя състезателен дух. С годините придобивах все повече и повече знания в тази област – в училище, а и след това в Технически Университет – София. Привлече ме това, че се разглеждат и инженерни дисциплини, и теми, а не чисто софтуерни, тъй като точните науки като математика, физика и химия винаги са били сред любимите ми. Навлизайки все повече в дебрите на познанието за чипове, логически елементи, операционни системи, fpga и прочие, разбрах, че моята страст е „оживяването“ на устройства които решават проблеми или помагат на хората в тяхното ежедневие. Не след дълго, преминавайки през допълнително специализирано обучение започнах и първата си работа като програмист на вградени системи в една компания за автомобилни устройства.
Като Head of Department, бихте ли споделили какви са предизвикателствата пред тази позиция и по-конкретно като част от структурата на Bosch?
По-интересните предизвикателства, пред които съм изправен на тази позиция са свързани с намирането на интригуващи проекти, разработвани с модерни технологии; намиране и развитие на кадри, които да бъдат вътрешно мотивирани да се справят с проектите и последващите ги трудности; осигуряване на всички необходими инструменти, лицензи и други условия, при които инженерите да се фокусират върху техническите проблеми, а не върху такива на средата. Bosch със своята дългогодишна история, изградена и изпитана структура, както и чрез връзките и отношенията си с партньори и клиенти, градени над столетие, предоставя една изключително удобна среда за моята работа чрез благоприятните условия за справяне с всяко едно от предизвикателствата.
В Bosch се разработват всевъзможни проекти за продукти и услуги, което ни дава огромен списък от възможности, от които да си избираме върху какво да работим. Освен това, всички необходими инструменти, условия и т.н., са налични и установени, и могат директно да се използват. Не на последно място, компанията, известна и със своята социална отговорност, предоставя и изключителни условия в личностно отношение за служителите.
По какви проекти работите, с какви технологии и кои са чисто технологичните предизвикателства пред тях?
Моят отдел работи по два типа проекти – продуктови и платформени.
Продуктовите проекти или по-скоро продуктовите програми (съвкупност от няколко сходни проекта), целят разработването на даден продукт за различни клиенти. Пример мога да дам с Interior Monitoring & Sensing – системи за автономно шофиране, свързани с разпознаване на това какво се случва вътре в автомобила. Сигналите, които се изпращат, в резултат на разпознатите сцени, движения и пр., се предават на други системи – централизирани, които могат да вземат решение какво следва да направи автомобилът. Тук технологичните предизвикателства са свързани с разработката, оптимизацията, интеграцията и обучението на алгоритми, както и оценката на тяхната работа. За да можем да внедрим една такава система в крайния автомобил е нужно тя да не допуска никакви грешки, защото това може да доведе до загуба на човешки живот!
Платформените проекти са такива, които поставят софтуерната основа за няколко продуктови линии на Bosch – смарт дисплеи, конвергентни продукти, както и вече споменатите системи за Interior Monitoring & Sensing. Основните предизвикателства са свързани с осигуряването на всички необходими функции за реализиране на бизнес функцията на даденият продукт, високата производителност, безпогрешна комуникация, липса на забавяния и други от подобен тип.
Всички проекти представляват така наречените вградени системи (embedded systems), т.е. миниатюрни компютърчета, 200-300 пъти по-малки от вашия лаптоп. За да се вдъхне живот в тях, нашите инженери пишат код на С++, Python и С, който посредством спомагателни устройства (debuggers), се програмира в embedded системата. Други технологии, свързани с AI, които използваме, са TensorFlow, OpenCV, ROS, Cuda, Keras, PyTorch и т.н.
Разработването на AI изисква прецизност откъм данни, сигурност, необходима е и сериозна изчислителна мощ за тежките алгоритми. За какви други аспекти е необходимо да внимаваме и да сме прецизни при разработката?
За мен изключително важна е и теоретичната подготовка. Разработването на AI не е никак просто нещо, макар че са налични много примери в Интернет, които човек за минути може да подкара на своя компютър. Истинското AI инженерство изисква познаването на много технологични аспекти, като как да си подберем данните за обучение, верификация и тестване на даден алгоритъм. Ако искаме да разработваме AI, свързан с разпознаване на изображения, трябва много добре да познаваме и теорията на IQ (image quality), тъй като малка промяна в параметрите на изображението – например гама или контраст, може да предизвика съвсем различни резултати от нашият алгоритъм. Необходимо е да се познават в детайли и методите, по които AI взема решение чрез невронни мрежи, дървета и/или друго.
За да твърдим, че разработваме истински AI, трябва да знаем толкова теория, колкото например се учи в университет за 1 година по всички предмети.

Бихте ли разказал по подробно за присъствието и употребата на невронни мрежи в изкуствения интелект?
Невронните мрежи представляват статистически модели, чрез които целим да обучим изкуствен интелект да извършва дадена задача. Тяхната поява е вдъхновена от нашия естествен интелект, като идеята им е да се наподоби човешкият мозък и неговата дейност. Определени изследвания оценяват броя на невроните в човешкият мозък на над 100 милиарда, като те са свързани помежду си и комуникират. Говорейки на едно новородено дете, например, то успява след известно време да научи звуците и думите, които произнасяме, изграждайки определени връзки между невроните в мозъка си. Така и даден алгоритъм (AI), след прилагане на правилен подход за обучение, може да изгради подобни връзки и да разпознава подобни звуци и думи.
За да създадем една невронна мрежа, която има много голяма точност на разпознаванията, подобно на човешкият мозък, са ни нужни огромно количество неврони. Това от своя страна изисква наличието на сериозна изчислителна мощ, за да работи една такава система в реално време. Именно поради бурното развитие на съвременните чипове и хардуер, имаме възможност да срещаме AI във все повече устройства от нашето ежедневие.
Говорейки за AI, то често след него се нарежда и ML – каква е враимовръзката между тях и може ли едното да съществува без другото?
Machine Learning (ML) е област в компютърната наука, която има за цел да научи даден алгоритъм да се самообучава, без да бъде изрично програмиран да го прави. По конкретно ML представлява подход за анализ на информация, който включва създаване и адаптиране на модели, които дават възможност на дадената програма/алгоритъм да се „самообучава“ чрез опит/и, подобно на хората.
За да разграничим най-просто ML и AI, може да кажем, че ML е това, което прави възможно създаването на програми и машини с изкуствен интелект (AI).

Фотограф – Лилия Йотова
Кои според Вас са най-добрите и полезни AI open source инструменти, които бихте препоръчал?
Всеки един свободно достъпен инструмент може да бъде полезен за определена задача. Многообразието от възможни AI реализации е именно предпоставката за наличието на многообразие и при инструментите. Даден инструмент може да е най-добър за конкретна работа, но за друга да изостава значително от друг такъв, затова не мога да кажа, че този или онзи е генерално най-добрият. Точно обратното, подбирането на най-правилния инструмент за свършване на определена задача е от изключителна важност за качеството.
Впоследствие, съвкупността от всички подбрани, формира едно множество на най-подходящите инструменти за решаване на даден AI проблем. Решаването на Computer Vision проблем, например, изисква доста различно множество, спрямо такъв, свързан с лингвистично разпознаване.
Разбира се съществуват и много популярни инструменти като OpenCV, TensorFlow, Keras, PyTorch, OpeNN и други, с които един инженер може винаги да започне, но в последствие е от изключителна важност, да се отсее правилният набор за конкретните нужди.
Кои са секторите, при които най-често се имплементират AI решения?
AI решения могат да се измислят и внедрят във всяка една сфера на човешката дейност. Няма абсолютно никакви ограничения. Най-популярните, отново свързани с Bosch, са автономните автомобили – пътнически, транспортни и т.н. Друга популярна сфера е навлизането на AI в смартфоните и устройства от бита на хората – хладилници, перални. От много години се използва AI за анализ и откриване на „patterns“ в данни, например при търговия на фондовите борси.
Малко известно е обаче, че AI се използва широко и отдавна в различни инженерни дейности – например в машини за разпознаване на дефекти по платки. Друга малко популярна област, но с голямо икономическо значение, силно застъпена в Bosch, е внедряването на AI в производствените линии, с цел намаляване на грешки, ранно откриване на проблеми и други.
AI е вграден в изключително много услуги, които хората използват в ежедневен план. Какви обаче са тънкостите за разработване на качествен AI? Какви насоки бихте дал?
Няколко са основните насоки, що се отнася до разработването на качествен AI. Най-основополагащата от тях е детайлното дефиниране на проблема, който искаме да решим – изясняването на „позитивния“ път (т.е. най-честите ситуации, в които нашият AI изпада), но също така и всички „негативни“, или т.нар. гранични случаи, които можем да си представим. В повечето случаи трябва да се вземат под внимание и законодателните уредби за конкретната дейност.
За качествен AI няма как да не отбележим, че е нужно не само огромно количество данни за съответните training, validation и test множества, но и тяхното многообразие. По този начин бихме се погрижили, че нашият AI ще е наясно с голяма част от сценариите, с които би се срещнал. Много важно е и различните множества от данни да са независими, защото в противен случай може да получим подвеждащи резултати. Например ако обучим нашия AI да се справя с N на брой ситуации, след което го тестваме със същите данни дали се справя с тях, ще получим доста задоволителни резултати – висока точност, малък брой false-positives и false-negatives. В действителност, когато той се изправи пред непозната ситуация, най-вероятно ще даде грешен резултат, поради ограниченото количество данни, с което е бил трениран. Много лесно можем да си представим този проблем ако се върнем около 120 години назад в човешката история. До началото на 20 век, когато е бил изобретен автомобилът, хората са се придвижвали на коне, с колелета, карети и всичко е било ясно и уредено. В един момент обаче, по улиците плъзват автомобилите, движещи се с по-висока скорост, с различни габарити, липса на правила за тях. В резултат на това се случват множество инциденти докато хората успеят да се „обучат“ как да се справят с новите ситуации.
Друга основна насока за достигането на качествен AI е правилният подход и подбор на алгоритми. Налични са огромно количество свободно достъпни такива. Постоянно се разработват и нови. Има нови научни изследвания и разработки за други. AI алгоритмите са като вселената – с всеки изминал момент се разширяват и размножават все повече и повече, и инженерите, които се занимават с AI, имайки предвид това, трябва да си поставят много ясни и точни критерии, какво искат да постигнат, за да не прекарат години само в изследвания.
И последно, но не на последно място – тестване, тестване, тестване и пак тестване! Изключително важен аспект, особено в нашата работа в Bosch, където от създаваните технологии зависи човешкият живот. Много компании се борят да са първите на пазара относно даден AI, но при нас, преди всичко е отговорното отношение, поради което бихме пуснали продукт на пазара само ако сме 110% сигурни, че сме тествали всички възможни комбинации, вариации и пермутации на сценариите на нашата система.

Фотограф – Лилия Йотова
Кои са основните принципи, които трябва да се знаят и изпълняват при внедряването на AI в продукти? Можем ли да говорим и за наличието на “слаб” AI? Как изглежда той и как да го разпознаем?
Слабият (weak) или още известен като тесен (narrow) AI се характеризира с това, че решава конкретни задачи и има лимитирана способност да се самообучава за все по широка област на действие. По-голямата част от съвременните AI решения са всъщност слаб AI – Siri на Apple, Newsfeed-a на Facebook, Google Assistant и други. Голяма част от системите за автономно шофиране също са weak AI.
Слабият AI може да се разпознае по това, че при грешка или неизправност, може да нанесе вреда; ако радарният круиз контрол на нашият автомобил, например, не изчисли правилно скоростта на движещия се пред нас автомобил, може да предизвика катастрофа. Също така, слабият AI може да се използва с недобронамерени намерения, които AI самостоятелно не може да отчете – напр. терористични атаки с безпилотни автомобили или самолети.
Какви са новите технологични тенденции по света в сферата на изкуствения интелект?
Все по-широкото приложение на AI решения в различни области изисква и промяна в инфраструктурата, на която се изпълнява, както и взаимодействието с нея. В този ред на мисли една от глобалните тенденции е все по тясната връзка между AI и Cloud решенията.
Друга област, която получава допълнително инерция, включително и от дистанционния метод на работа, е Voice & Language изкуственият интелект. Конкретно в множество customer support центрове се интегрират решения за автоматизирано разпознаване на говор на различни езици.
От друга страна, експоненциално нарастващият обем данни, които се получават от личните устройства, които хората използват – телефони, смарт часовници, фитнес гривни, камери и т.н., засилва тренда в употребата на изкуствен интелект за структуриране на данни и откриването на свързани характеристики (patterns).
Не на последно място е и тенденцията за все по тясна взаимовръзка между AI и IoT продуктите. Именно този тренд е избран за основен за Bosch в идните години.

На годишната конференция на Bosch бе споменато, че компанията има за цел да се превърне във водеща AIoT организация. Какво би представлявало това и какви са разликите между IoT и AIoT? Ще се говорили все по-често за второто?
IoT продуктите навлизат много силно в последните години. Това са различни устройства, които следят и събират дадена информация от реалния свят. Посредством връзка с интернет, данните се предават към услуги, които предоставят някакво “added value” за човека. Например фитнес гривната следи фазите на вашия сън, след което ги изпраща към сървър, където те се сравняват с данните от много други хора и се поставя оценка за качеството на вашия сън. Друг обществено значим пример би било уличното осветление. В някои градове има IoT системи, които според определени параметри регулират осветеността с цел ефективност и пестене на енергия. Също така, тук може да споменем и IoT системата за засичане на бръмбари по посевите.
С други думи, инфраструктурата от различни IoT системи и устройства, събиращи информация, е налице. Както вече говорихме, когато имаме много информация и искаме да направим нещо полезно с нея, намесваме AI. От тук идва и AIoT – симбиозата между AI и IoT за автоматизирано решаване на казуси от ежедневния живот на хората и света.
Bosch, спазвайки мотото си „Invented for Life“, намира своето прозвище именно в тази нова тенденция – AIoT.
В Bosch дори вече са разработени и внедрени подобни AIoT системи – за засичане, разпознаване и автоматизирано справяне с възникнали неизправности в заводите в Ройтлинген и Хомбург.
Съществуват ли технологии, които ще набират сила?
Разбира се, технологиите никога не „спят“. Следете редовно дейността на Bosch Engineering Center Sofia и скоро ще научите за някои от тях.
За финал, бихте ли споделили кои са Вашите любими AI разработки? Такива, които са интересни, а същевременно могат и да послужат като ролеви модел за технологията.
Най-важното за мен с всички нови технологии, не само AI, е те да служат и да помагат на хората и на света. Всякакви решения в насока справяне с глобални проблеми – замърсяване, глад и т.н., за мен са ролеви модели, които трябва да се следват и развиват.
Изхождайки от своята идеология, Bosch разработва именно такива системи и поради това смятам, че те могат да бъдат ролеви модели.
AIoT системата за предпазване на насажденията от вредни насекоми на Bosch се бори с проблема с глада по света. Само миналата година нашествията на скакалци в Африка и Близкия изток унищожиха огромни площи с посеви в Египет, Пакистан, Йемен и други – част на света, която и без друго е силно засегната от липсата на достатъчно хранителни продукти. Други подобни нашествия от насекоми в последните години имаше и в САЩ и Австралия.
Друг пример, който бих дал, разработван от Bosch, е AIoT система за управление дейностите в големи фабрики. Система, която не само оптимизира времето и процесите на производство, но е и доказано намаляваща разходите за енергия с до 20% и вредните емисии от производствената дейност с до 35%.
]]>Разработването на комплексни мобилни приложения, които отговарят на високите очаквания на потребителите и същевременно консумират API със сървисно ориентирана архитектура, може да бъде предизвикателство в наши дни.
Нека разгледаме следните предизвикателства, с които бихме могли да се сблъскаме, докато работим върху реални приложения:
1. Междуфункционална комуникация;
2. Оптимизиране на API заявки, като спазваме добрите UX практики;
3. Изграждане на приложение, което може да обработва стотици хиляди, променящи се записи.
Междуфункционална комуникация
Представете си, че работите върху приложение, което има модули комуникиращи помежду си. Примерно списъци с обекти, които потребителят може да маркира като предпочитани или да променя по друг начин.
Нека да видим как би изглеждало това, ако приемем, че имаме два списъка. Първият съдържа всички обекти, а вторият тези, които сме маркирали като любими.
Потребителите виждат просто два списъка, но ние като софтуерни инженери виждаме много повече.
Нека приемем, че конкретния state management, който сме избрали за този проект, е BloC (Business Logic Component), с което трябва да имплементираме BloCs като FavoritesBloc, SearchBloc, ExtraDetailsBloc, PuppyManageBloc и др. Когато някой от обектите се актуализира и двата списъка (търсене и любими) трябва да бъдат актуализирани своевременно.
Бихме могли да подходим към комуникационното предизвикателството между модулите като създадем зависимости между блоковете. BloC A може да зависи от BloC B, BloC B от BloC C и т.н., но така може да се окажем с циклични зависимости, които се управляват трудно.
Нека видим как Coordinator шаблонът може да ни помогне.
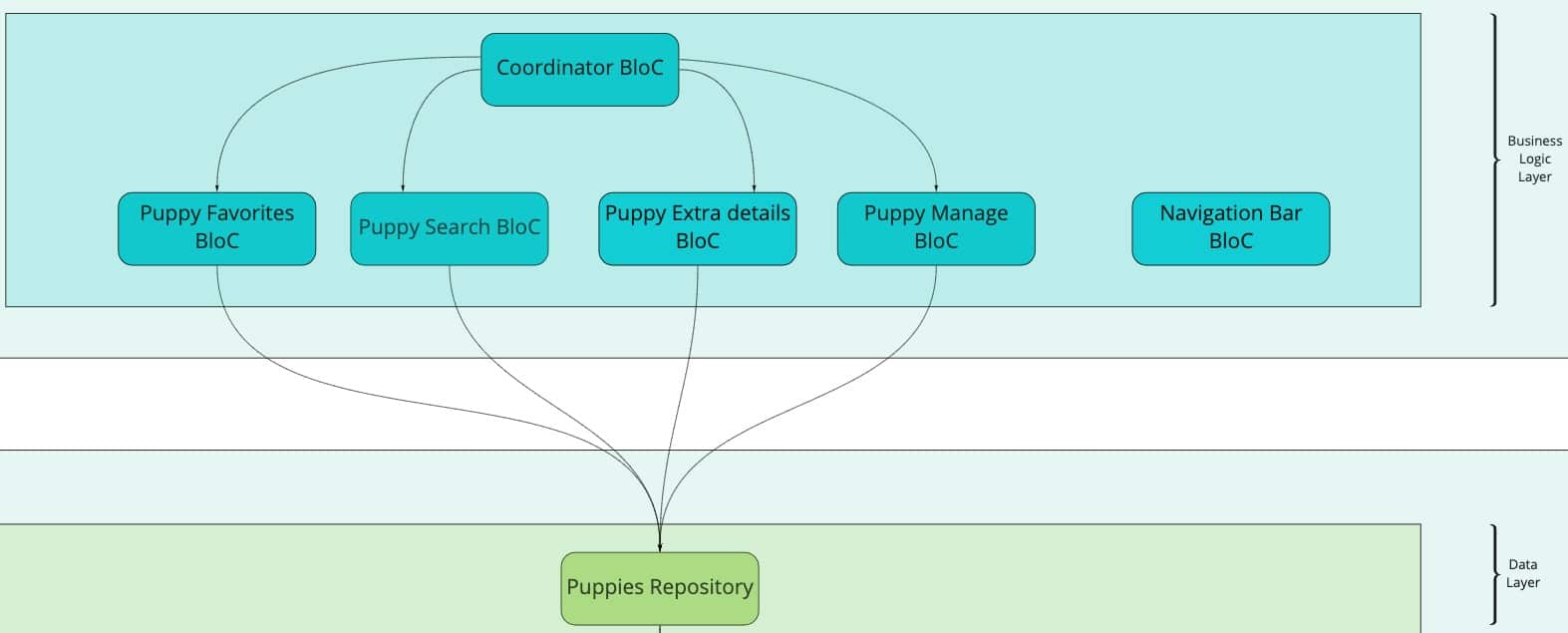 Сега имаме централно място за междублокова комуникация. Така елиминираме преките зависимости между блоковете . Всеки BloC изпраща събития към Coordinator BloC-а и всеки BloC може да слуша за събития и да реагира своевременно.
Сега имаме централно място за междублокова комуникация. Така елиминираме преките зависимости между блоковете . Всеки BloC изпраща събития към Coordinator BloC-а и всеки BloC може да слуша за събития и да реагира своевременно.
Оптимизиране на API заявки, като спазваме добрите UX практики
Изграждането на API със сървисно ориентирана архитектура го прави скалируем, но понякога API endpoints стават много фрагментирани, с което трябва да се справим по някакъв начин в мобилното приложение.
Представете си, че с първата API заявка приложението може да извлече списък с обекти, но след това потребителите трябва да получат някои допълнителни детайли, които трябва да бъдат заредени по-късно, както е показано по-долу.
1. Приложението трябва да извлече допълнителните детайли чрез отделни API заявки, когато потребителите скролират бавно.
2. Приложението трябва да събере всички видими обекти и да получи тези допълнителни детайли само с една API заявка, когато потребителят скролира бързо и след това внезапно спре.
Сега изглежда подходящ момент да видите някакъв код, нали така?
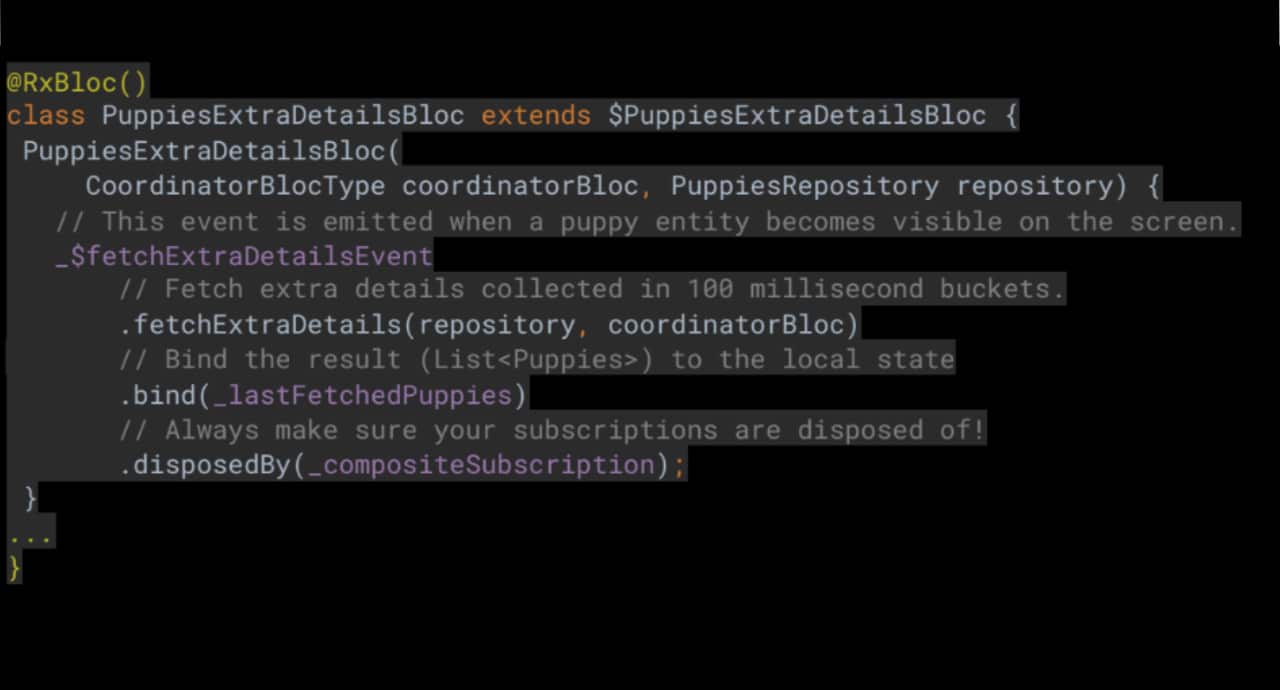
puppies_exstra_details_bloc_extentions.dart
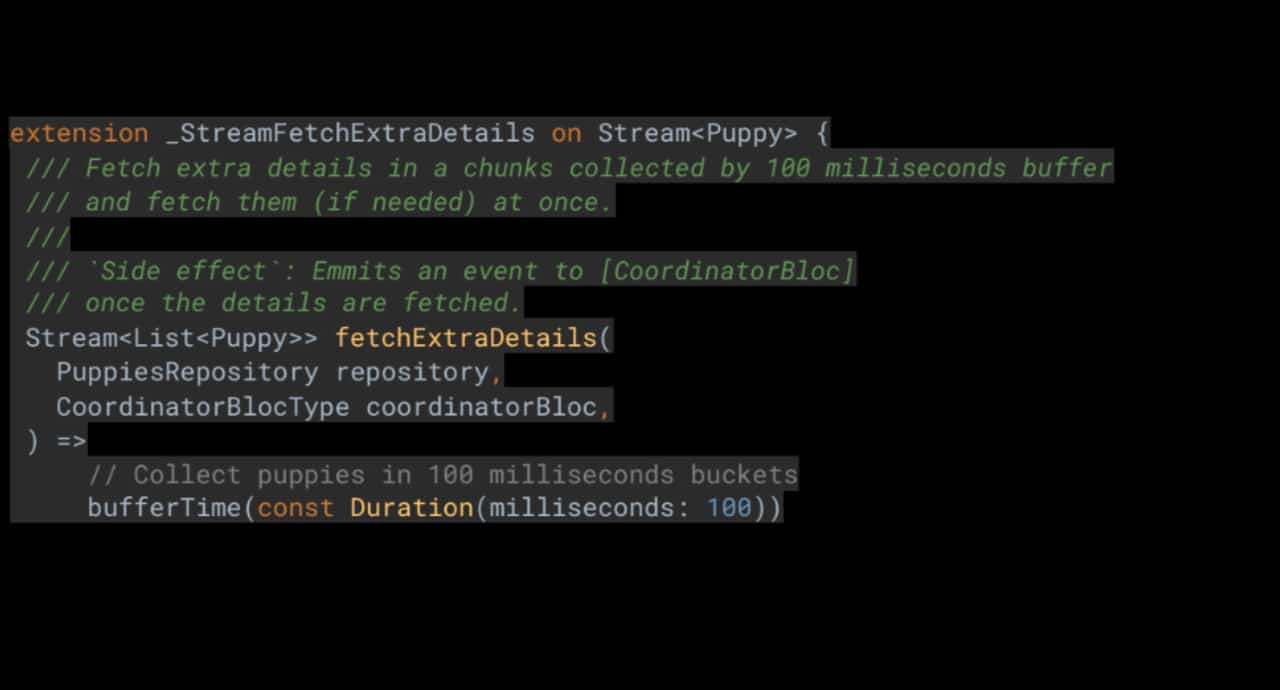
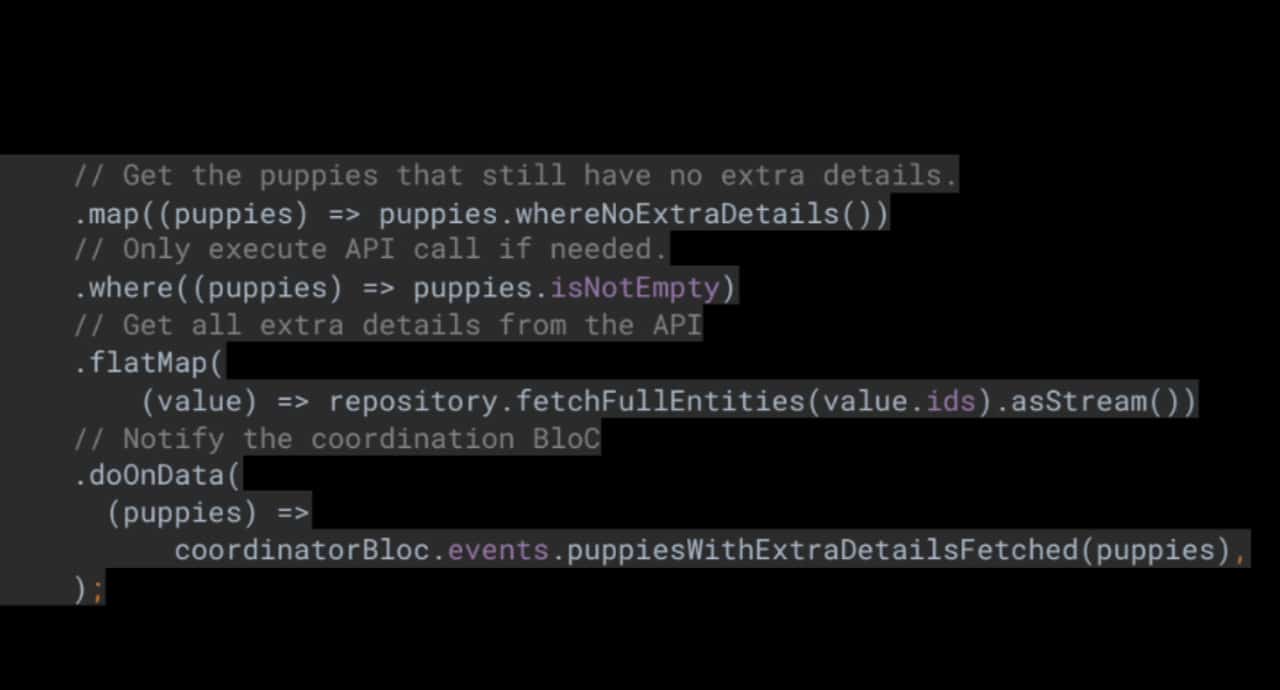
Използвайки този пакет, UI слоят може да изпрати видимите обекти към Business слоя. Тогава Business слоят може да ги буферира в 100 милисекунди интервали. Това означава, че бизнес слоят ще събира обекти и ще чака най-малко 100ms преди да извлече действителните допълнителни детайли. Така предоставяме най-добрия UX и в същото време постигаме оптимизация на API заявките.
Изграждане на приложение, което може да обработва стотици хиляди променящи се записи
Както знаем, Flutter е оптимизиран да работи много ефективно, но какво ще стане, ако трябва да доведем тази технология до предела на силите ѝ? А ако трябва да обработим стотици хиляди записи и същевременно искаме приложението да работи бързо и безпроблемно? Нека да видим как можем да постигнем това.
Опция 1
Можем да създаваме обекти от PuppyManage BloC, докато потребителят скролира през списъка. Това гарантира, че допълнителните детайли се извличат само, когато е необходимо и приложението все още отговаря на изискванията за оптимизирани API заявки, споменати по-горе.
Дотук добре, но така бихме имали един голям проблем, свързан с производителността на приложението. Когато потребителят скролира бързо, приложението трябва да създаде множество BloC обекти и същевременно потребителският интерфейс трябва да създаде множество BloC state subscriptions… съответно приложение ни ще стане много бавно.
Опция 2
Да създадем само един обект от всеки тип BloC, като например FavoritesBloc, SearchBloc, ExtraDetailsBloc, PuppyManageBloc и др. Нека да видим как би изглеждало това.
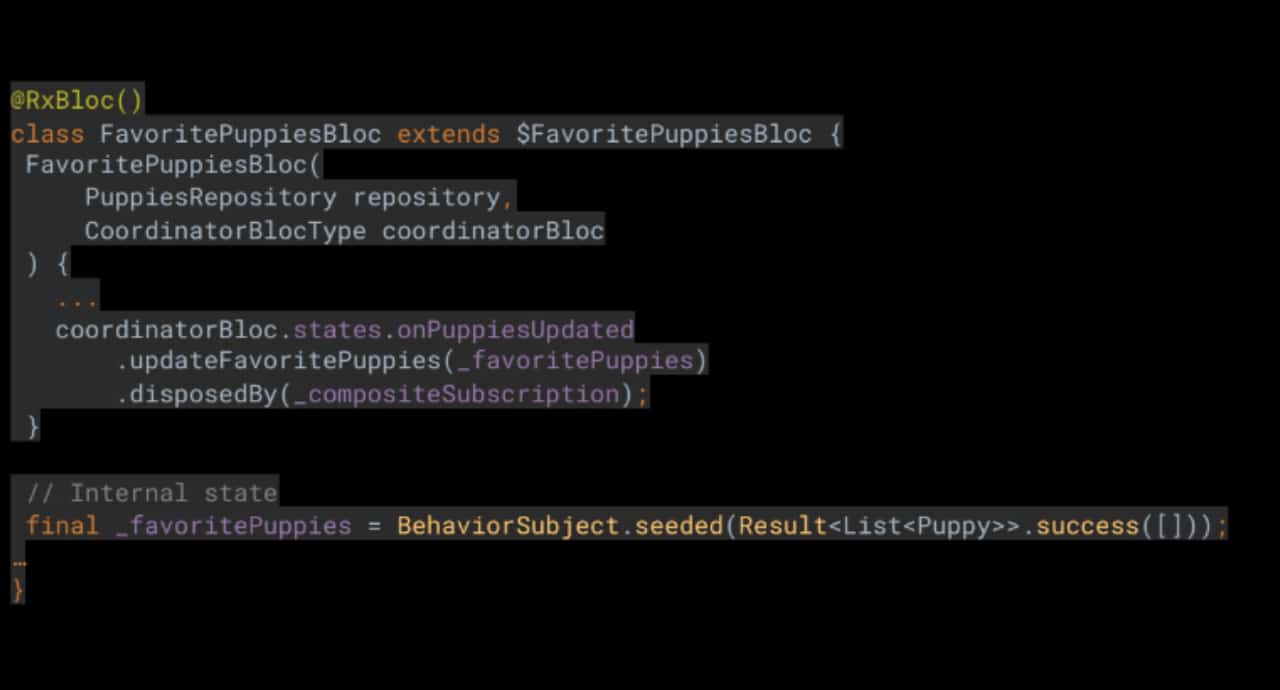
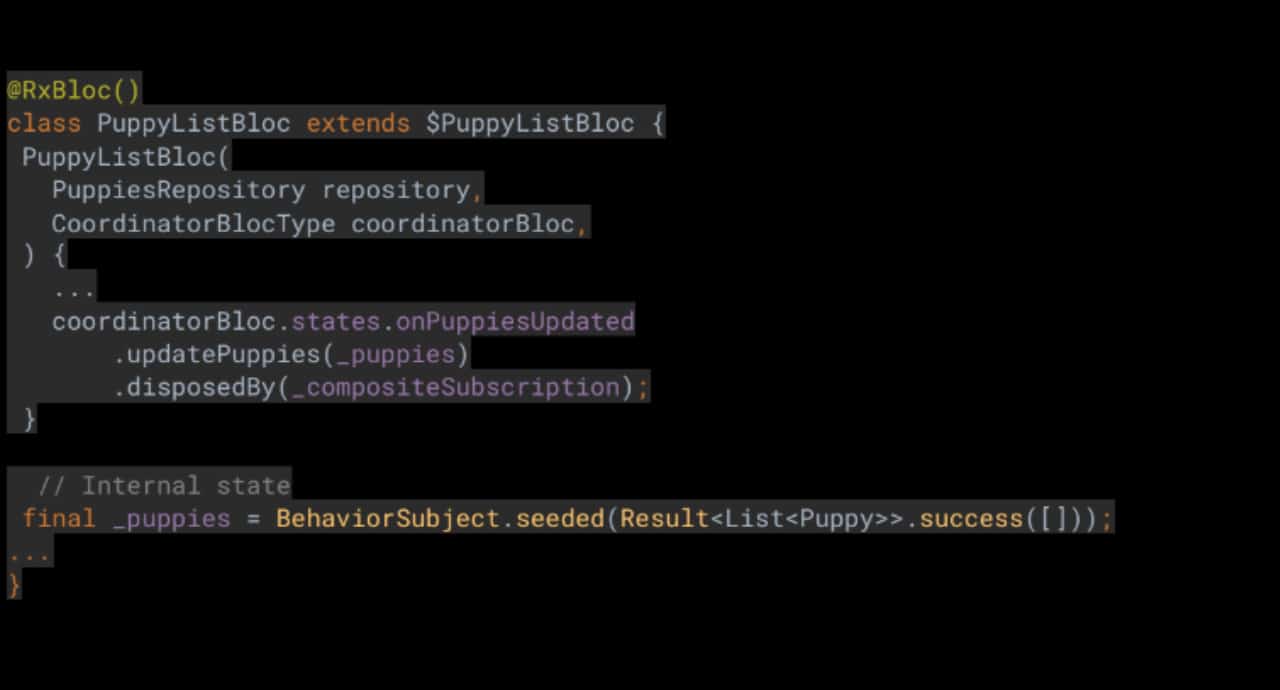
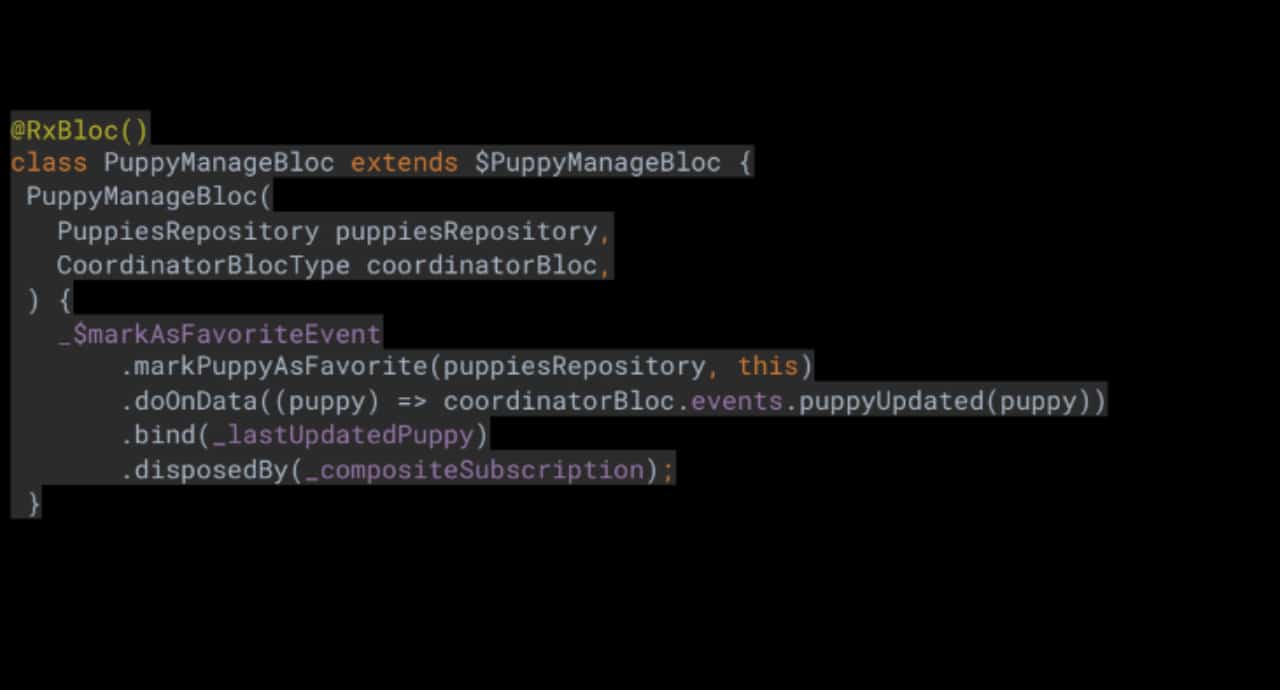 Можете да видите, че както търсачката, така и списъкът с любими имат собствен internal state, който се актуализира спрямо актуализациите на обектите, изпратени от ManagePuppy BloC чрез CoordinatorBloc. Това работи не само за маркиране на обект като любим, но и за извличане на допълнителни детайли. Чудесно, но задръжте за секунда … това означава ли, че имаме списък със стотици хиляди записи, които трябва да се актуализират спрямо всяка промяна? И приложението все още работи безпроблемно? Както споменах по-рано, Flutter е много бърз, така че да, приложението все още работи безотказно.
Можете да видите, че както търсачката, така и списъкът с любими имат собствен internal state, който се актуализира спрямо актуализациите на обектите, изпратени от ManagePuppy BloC чрез CoordinatorBloc. Това работи не само за маркиране на обект като любим, но и за извличане на допълнителни детайли. Чудесно, но задръжте за секунда … това означава ли, че имаме списък със стотици хиляди записи, които трябва да се актуализират спрямо всяка промяна? И приложението все още работи безпроблемно? Както споменах по-рано, Flutter е много бърз, така че да, приложението все още работи безотказно.
Архитектура: голямата картина
rx_bloc улеснява прилагането на BLoC state management, използвайки силата на реактивното програмиране.
Следвайки най-добрите практики за изграждане на стабилни мобилни приложения, архитектурата по-долу може да се използва заедно с BloC слоя.
Този пакет е създаден да работи заедно с rx_bloc_test, flutter_rx_bloc и rx_bloc_generator.
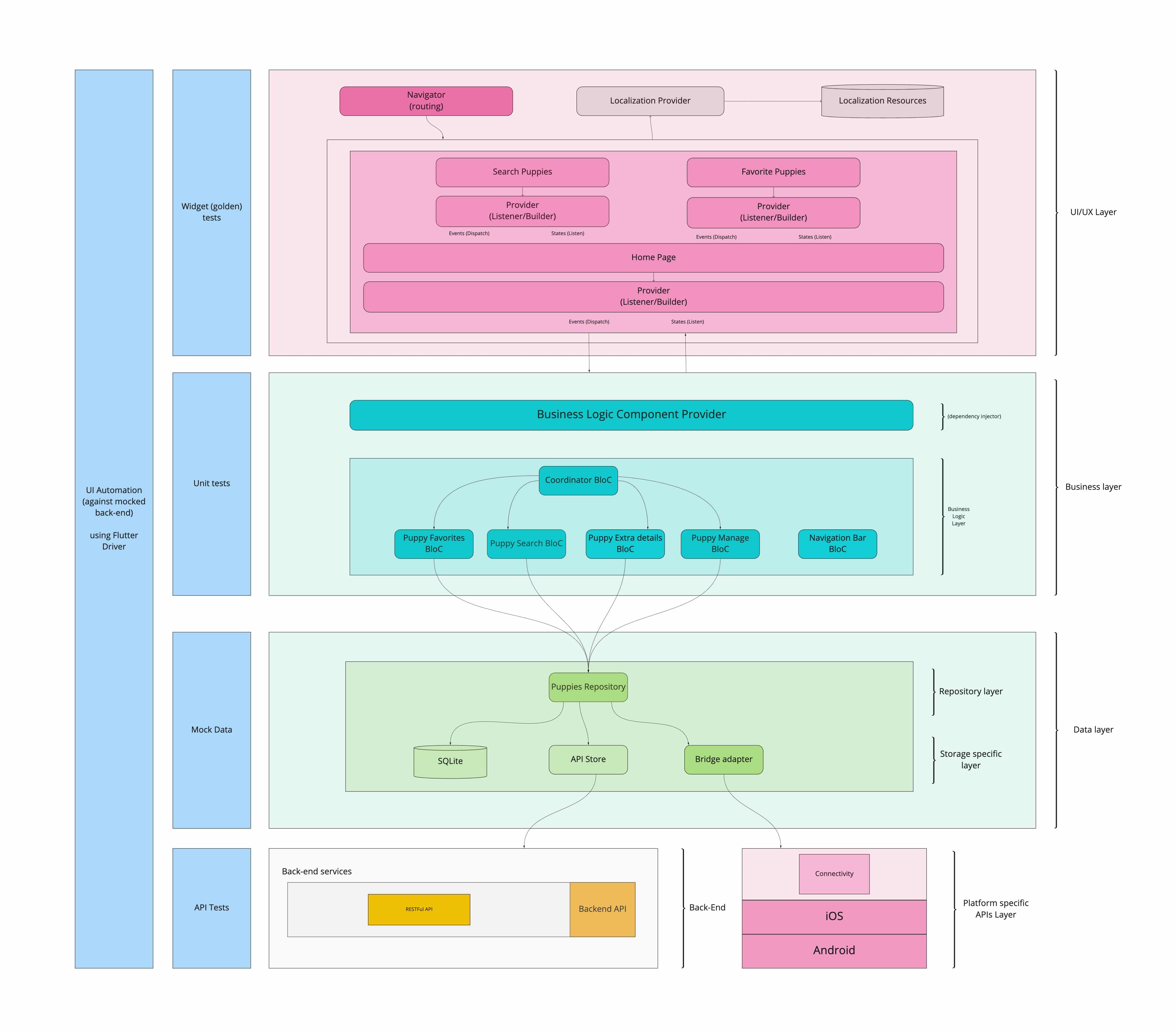
Заключение
Изграждането на приложения с реактивно програмиране в комбинация със солидна архитектура е наистина полезно. Приложенията стават по-стабилни, мащабируеми и по-лесни за поддържане.
Инвестирането в добра архитектура преди започване на нов проект винаги се отплаща в дългосрочен план.
Автор: Георги Станев, Technical Lead и Full-Stack Developer в Prime Holding JSC
]]>Работата ти в Strypes е многопластова и освен developer, Вие сте и Technical Lead, а също така водите и курсове, и трейнинги на фирмено ниво. Как успявате да съчетавате функциите си и как това влияе на софтуерните решения, които Strypes предлага?
Трейнингите са специфични за езиците и технологиите, които използваме, като в моя случай става дума конкретно за Python. Някои от уроците са на доста сериозно ниво и наблягат на различни дизайн принципи, добри практики за програмиране и т.н. Съвсем не са на ниво за junior обучение и това как се пише на Python. Подготовката за тези курсове също дава доста добър поглед относно моето разбиране върху проблемите и use case-овете, с които се налага да се справяме някой път. Поради тази причина, трейнингите са добри както за мен, така и за моя екип. Дават ми повече перспектива и дълбочина на знанията, които имам и които след това прилагаме при проблемите, срещани в работния процес.
Като Technical Lead – Вие самият продължавате ли да кодите?
Има две страни на монетата. За щастие все още успявам да се докосвам до код, защото в крайна сметка работата не става само с даване на съвети и правене на ревюта. Човек трябва да има досег с кода, въпреки че има една идея повече срещи, абстрактни дискусии и т.н. Зависи от проекта, но някой път пиша немалко. Факт е, че не е 70-80% от времето, както би могло да бъде, но Technical Lead-ът е едно друго предизвикателство, което е много интересно и по никакъв начин не съжалявам, че ми отнема сериозна част от времето, което бих прекарал в писане на код.
Като такъв Lead, предполагам е необходима доста по-голяма комуникация с клиента, повече разбиране на бизнес частта?
Определено има повече разписване на изисквания, документи и комуникация. Изключително важно е да съм мост между колегите и изискванията на клиента, при имплементирането на нещо функционално. Необходимо е постоянно да се питаме – „защо трябва да го направя?“. Този въпрос е ключов и дава много отговори и перспективи. Аз работя с умни и талантливи хора, но опитът позволява повече на мен, а не толкова на тях, задаването на такъв тип въпроси. Важно е да търсим най-доброто решение за всички нужди на клиента, а не просто да се фокусираме върху техническата част.
Все пак има всеизвестен слух, че програмистите не обичат много да се срещат с клиента. Тоест Вие трябва да сте посредник между двете звена.
Имам приятел, който след срещи винаги задава въпроса „имаше ли причина тази среща да не бъде просто един имейл?“. В даден момент спряха да го канят. Но в общи линии това е част от длъжностната характеристика на тази роля. Колкото и да ми се иска всичко да се реши с имейл, то не винаги може да се получи така, докато съществува постоянна нужда от моста между разработчиците и клиента. Разбира се, тази отговорност не е изцяло моя, защото все пак имаме. Project Manager/Product Owner, който поема голяма част от задачите в тази област.
Цялото интервю с Виктор Бечев предстои да излезе в ЧАСТ II на специалното издание на DevStyleR “ТОП Софтуерните Компании”.
[contact-form-7] ]]>За да научите повече за основните промени в Android 11, разгледайте таблицата по-долу:
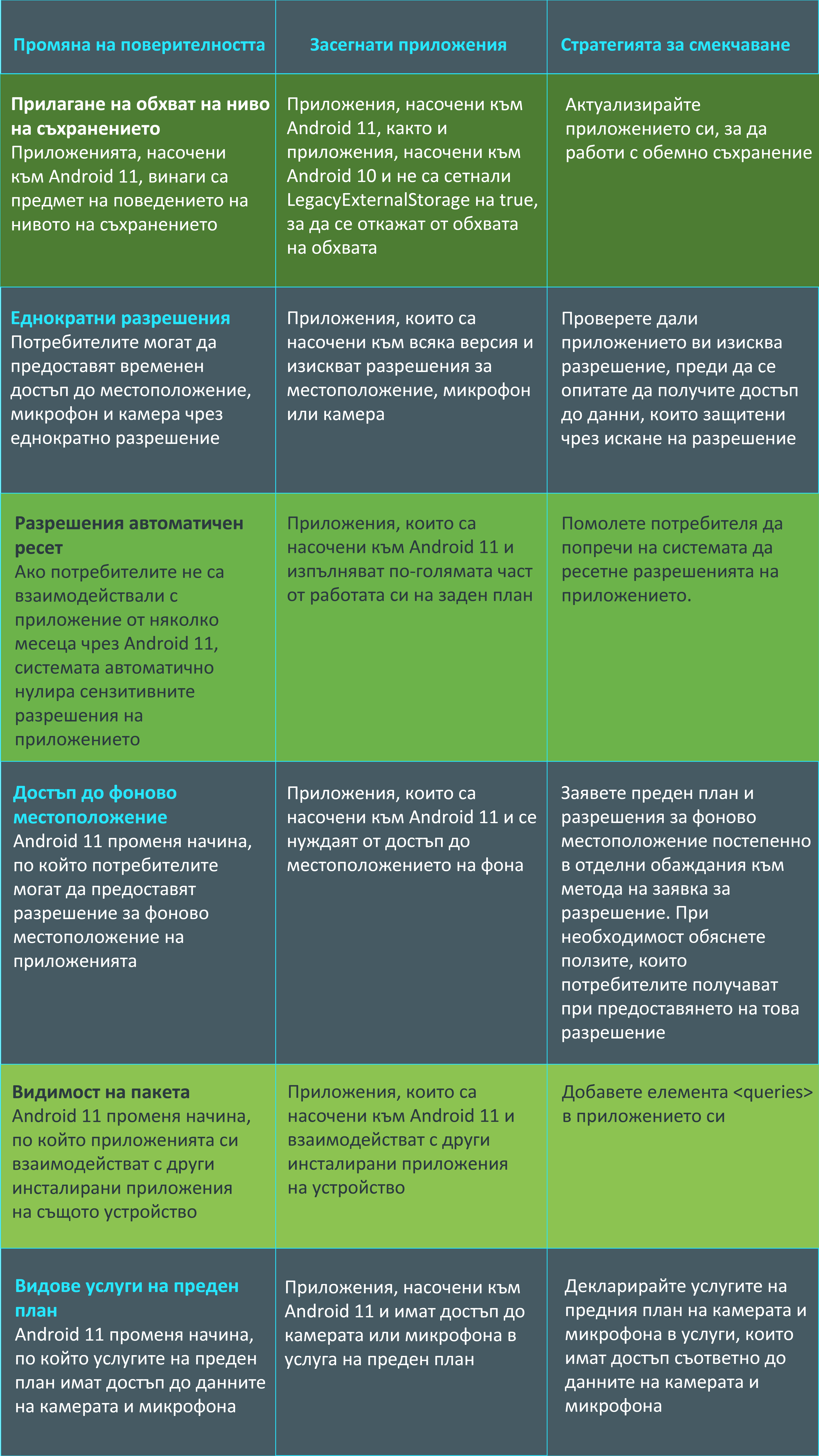
Как да започнем с актуализациите за поверителност – основни стъпки?
- Разгледайте функциите за поверителност. Вижте как приложението ви съхранява файлове и потребителски данни, разрешения за заявки и местоположение. В допълнение прегледайте как приложението взаимодейства с други приложения, помислете дали да има нужда от преглед на данните, до които вашето приложение има достъп и определете дали приложението трябва да декларира новите видове услуги на преден план.
- Тествайте приложението си на Android 11.
- Актуализирайте приложението си.
 Progressive Web App (PWA) е технологията, която ще промени начина на работа на уеб базираните услуги. Стъпвайки върху функционалностите на уеб браузърите, тази технология отваря достъпа до съответния ресурс на клиенти от всички платформи. Популярните магазини за приложения (Мicrosoft Store, Apple App Store и Google Play Store) вече отвориха врати за подобен тип приложения.
Progressive Web App (PWA) е технологията, която ще промени начина на работа на уеб базираните услуги. Стъпвайки върху функционалностите на уеб браузърите, тази технология отваря достъпа до съответния ресурс на клиенти от всички платформи. Популярните магазини за приложения (Мicrosoft Store, Apple App Store и Google Play Store) вече отвориха врати за подобен тип приложения.
Популяризирането на технологията се осъществява след като Twitter решават да експериментират с въвеждането ѝ за мобилните си потребители. Днес PWA е част от повечето продукти, предоставяни и от основни имена като Google и Microsoft.
Функционалности
Необременени от специфичен уеб framework и програмен език, функционалностите, които PWA предоставя, се доближават до native приложенията, благодарение на развитието на следните браузър функции:
- Offline support — посредством service-worker кешира и запазва всички необходими файлове за работа в offline режим
- Home screen install — директна инсталация през браузъра, не през някой от магазините за приложения
- Push Notifications — абониране на потребителите за онлайн известия
- Biometric Authentication — с развитието на браузърите и достъпа им до Biometric API на всички устройства този feature е вече част и от PWA
- URL PWA Integration — при вече инсталиран PWA връзката ще бъде отворена в приложението
- Navigation Bar Color — с добавянето на manifest.json файла и
theme_colorпропъртито задаваме фона на navigation bar компонента в браузъра
Технологията отблизо
manifest.json
Описващ с пропъртита всичко необходимо за вашето приложение. В този файл може да се намери име на приложението (short_name и name) и описание (description), икони, появяващи се във всички платформи (icons object) и start_url — тук важно е страницата да е статична и да може да работи offline. Наред с гореизброените присъсъва и пропърти за цветовете в приложението (background_color, theme_color), както и scope — индикира дали сайтът е напълно под PWA или от определена част от нея.
{
"short_name": "Weather",
"name": "Weather: Do I need an umbrella?",
"description": "Weather forecast information",
"icons": [
{
"src": "/images/icons-192.png",
"type": "image/png",
"sizes": "192x192"
},
{
"src": "/images/icons-512.png",
"type": "image/png",
"sizes": "512x512"
}
],
"start_url": "/?source=pwa",
"background_color": "#3367D6",
"display": "standalone",
"scope": "/",
"theme_color": "#3367D6"
}
service worker
Скрипт, който бразърът стартира на заден план, отделно от уеб страницата, обхождайки всичко в зададения scope, за да може приложението да работи бързо, ефективно и, най-важното, offline. В момента service-woker поддържа push notifications и background sync. В бъдеще се очаква функционалността му да се разшири с периодична синхронизация и location ограничения.
Важно е да знаем:
* Това е JavaScript Worker
* Програмируемо proxy, коeто позволява контрол на мрежовите заявки
* При неизползване се терминира автономно
* При нужда се рестартира самостоятелно

ngsw-config.json
Конфигурация, описваща файловете, които service worker обхожда и кешира, както и метода на зареждане.
{
"index": "/index.html",
"assetGroups": [
{
"name": "app",
"installMode": "prefetch",
"resources": {
"files": [
"/favicon.ico",
"/index.html",
"/*.css",
"/*.js"
]
}
}, {
"name": "assets",
"installMode": "lazy",
"updateMode": "prefetch",
"resources": {
"files": [
"/assets/**",
"/*.(eot|svg|cur|jpg|png|webp|gif|otf|ttf|woff|woff2|ani)"
]
}
}
]
}
Предимства на PWA
- Бърз и лесен за интеграция във всички уеб приложения
- Използва всички иновации, добавяни в уеб браузърите
- Работа offline
- Доближаващ се все повече до core функционалностите на native apps
- Съкратен release cycle — всичко в едно.
- Без нужда от update в магазините за приложения
- Сигурността, която уеб базираната услуга предоставя, бива пренесена в своята цялост и на мобилното приложение
- Високо качество на продукта
Elasticsearch е едно от най-популярните приложения за търсене в днешно време, което се използва в редица приложения (като Wikipedia, Stackoverflow и много други). Базирано е на Lucene библиотеката за търсене и една от основните функционалности, които предлага е JSON-базиран език за писане на заявки, които е изграден над Lucene и предоставя доста лесен механизъм за взаимодействие с Elasticsearch платформата. Поддръжката за SQL добавена в Elasticsearch 6.3 предоставя стандартен механизъм за изпълнение на заявки за търсене и е стъпка напред към по-лесното използване на Elasticsearch от страна на програмистите.
Въпреки че стандарта SQL е разработен основно за работа с релационни бази данни, той е вече успешно реализиран в редица нерелационни бази данни (каквато е и Elasticsearch). Други такива пример включват например и приложения като Apache Spark или Apache Ignite (където SQL е в основата на самото приложение). В тази статия ще разгледаме накратко как работи Elasticsearch SQL.
Предварителен сетъп
За да изпробвате примерите показани в статияте е необходимо да си инстралирате и стартирате локално Elasticsearch (поне версия 6.3). В статията е използван Elasticsearch 7.5. Първо ще създадем posts индекса, който съхранява постове за даден форум. Ще използваме официалния Elasticsearch Java клиент , за да добавим данни в индекса без да указваме експлицитно схема за полетата в индекса (Elasticsearch ще я създаде за нас автоматично в такъв случай).
Необходимо е да създадем Maven проект със зависимост към Elasticsearch Java high level client библиотеката:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.5.0</version>
</dependency>
Ще създадем 10000 генерирани документа в posts индекса като използваме следния код:
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder( new HttpHost("localhost", 9200, "http")));
String[] possibleUsers = new String[] {"Martin", "Jim", "John"};
String[] possibleDates = new String[] {"2019-12-15", "2019-12-16", "2019-12-17"};
String[] possibleMessages = new String[] {
"Hello, Devstyler !",
"Cool set of blog posts. We want more !",
"Elasticsearch SQL is great."};
for (int i = 1; i <= 10000; i++) {
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("user", possibleUsers[ThreadLocalRandom.current().nextInt(0, 3)]);
jsonMap.put("date", possibleDates[ThreadLocalRandom.current().nextInt(0, 3)]);
jsonMap.put("message", possibleMessages[ThreadLocalRandom.current().nextInt(0, 3)]);
IndexRequest request = new IndexRequest("posts")
.id(String.valueOf(i)).source(jsonMap);
client.index(request, RequestOptions.DEFAULT);
}
client.close();

Изпълнение на SQL заявките
Може да използваме Kibana, за да потърсим всички документи, които отговарят на потребителя Martin:
POST /_sql?format=txt
{
"query": "SELECT * FROM posts where user = 'Martin'"
}
Друг пример е заявка, която брои всички документи, които съдържат ключовата дума:
POST /_sql?format=txt
{
"query": "SELECT count(*) FROM posts where message like '%Devstyler%'"
}
Ако искаме да изпълним горните заявки през Java приложение имаме няколко опции:
Да използваме Elasticsearch JDBC драйвъра, който обаче е наличен в platinum и enterprise версиите на Elasticsearch;
Да използваме REST клиента на Elasticsearch, които е наличен и в базовата (безплатна) версия.
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.5.0</version>
</dependency>
Следния пример връща 10 документа от posts индекса:
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200, "http")).build();
Request request = new Request("POST", "/_sql");
request.setJsonEntity("{\"query\":\"SELECT * FROM posts limit 10\"}");
Response response = restClient.performRequest(request);
String responseBody = EntityUtils.toString(response.getEntity());
System.out.println(responseBody);
restClient.close();

За да видим как в действително се изпълнява дадена SQL заявка от Elasticsearch може да използваме translate функционалността предоставена чрез /_sql/translate адреса в Elasticsearch. Може да изпълним следния код в Kibana, за да видим как в действително SQL заявката се транслира до JSON-базирана Elasticsearch заявка:
POST /_sql/translate
{
"query": "SELECT * FROM posts limit 10",
"fetch_size": 10
}
Трябва да получим резултат подобен на следния:
{
"size" : 10,
"_source" : {
"includes" : [
"message",
"user"
],
"excludes" : [ ]
},
"docvalue_fields" : [
{
"field" : "date",
"format" : "epoch_millis"
}
],
"sort" : [
{
"_doc" : {
"order" : "asc"
}
}
]
}
Elasticsearch SQL характеристики
Видяхме как да изпълняваме заявки в Elasticsearch SQL. В действителност имплементацията на SQL в Elasticsearch е доста богата и включва:
- Различни варианти за форматиране на резултата от SQL заявката (csv, json, yaml и други);
- Използване на JSON-базирани заявки като филтри към дадена SQL заявка;
- Команден инструмент за изпълнение на SQL заявка предоставен от elasticsearch-sql-cli инструмента в инсталацията на Elasticsearch;
От гледна точка на самия SQL стандарта следните страница описва в детайли, какво е реализирано като команди, функции и оператори:
https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-commands.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-functions.html
Заключение
В тази статия демонстрирахме как да използваме Elasticsearch SQL, за да взаимодействаме с Elasticsearch платформата. Има голяма вероятност този механизъм да се наложи над JSON-базирания език за писане на заявки. Въпреки това SQL не е алтернатива на JSON-базирания език, а по-скоро допълнение изградено над него.
Мартин Тошев е ИТ консултант, Java ентусиаст и поддръжник на българската Java User Group. Като такъв, неговите интереси са обвързани с всички технологии около Java, както и Cloud Computing technologies, облачни софтуерни архитектури, Enterprise приложения и NoSQL бази данни.
]]>