
Ракът е втората водеща причина за смъртта в световен мащаб, което определя търсенето на по-ефективни противоракови лекарства за глобално усилие. В битката се включва и групата по Биология на изчислителните системи в IBM Research lab в Цюрих, която изгражда подходи за машинно обучение. ML технологията може да помогне за по-добро изучаване на заболяването, водещите двигатели и молекулярни механизми, както и разликите в туморния състав, които се срещат в различни видове рак.
На големи научни събития през тази седмица IBM представи значителни свои изследвания, които водят до откриването на три нови ML решения в помощ на борбата срещу рака. Ето какви са те:
PaccMann – Deep Learning в помощ на лекарствата срещу болестта
Според официалното изказване на IBM новата PaccMann технология представлява система за прогнозиране на чувствителността на противораковите съединения с многомодални невронни мрежи. Технологията от най-ранен етап идентифицира най-ефективните “съединения”, които могат да помогнат в борбата с целевата болест. Чрез данни от различни източници, става възможно предсказването на това как клетките в болката тъкан ще реагират, ако се започне лечение с дадено лекарство. Deep Learning метода спестява стотици милиона долари, които отиват в разработка и получаване на противоракови лекарства чрез усъвършенствания си алгоритъм.
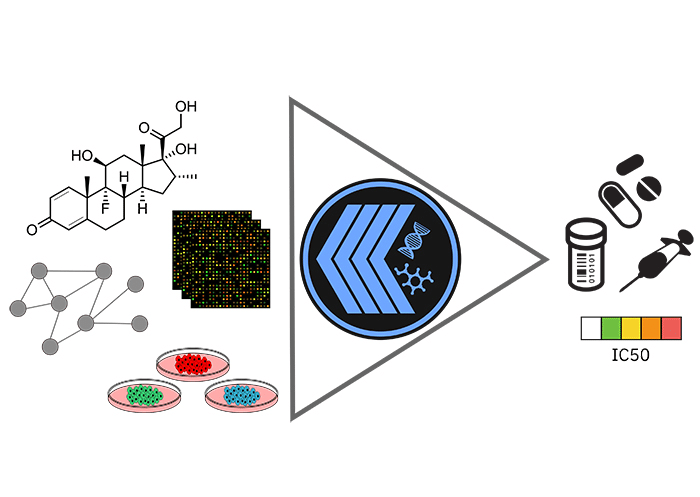
В тестовете учените са използвали PaccMann, за да предвидят чувствителност към лекарство чрез база данни и резултатът се е оказал по-точен, отколкото алтернативните инструменти, налични към този момент. Освен това технологията сама дава аргументация и подчертава кои специфични гени и кои части от молекулната структура на съединението са решаващи за финалната й прогноза. Тази информация може да бъде използвана за подобряване на съществуващи лекарства, както и за разработка на нови.
INtERAcT: Автоматизация на извличането на информация от научни проучвания
INtERAcT (Interaction Network infestance of vectoR представяния на думи) е нов подход за извличане на информация от научни статии, без нужда от човешка намеса.
При заболявания като рак нарушените биологични процеси се отразяват на взаимодействията между протеините. На тази тема са направени много проучвания, но тази информация е практически необятна и “погребана” – било то под формата на текст, изображения или графики в различни научни публикации по цял свят. Според скорошно библиометрично проучване стана ясно, че средно годишно се публикуват около 17 000 научни статии в областта на изследванията на рака – и продукцията продължава да нараства експоненциално. Новата разработка има за цел да помогне на всеки учен да прочете всички съществуващи публикации по темата, които са му нужни, на един дъх – без нужда да губи излишно време и усилия.
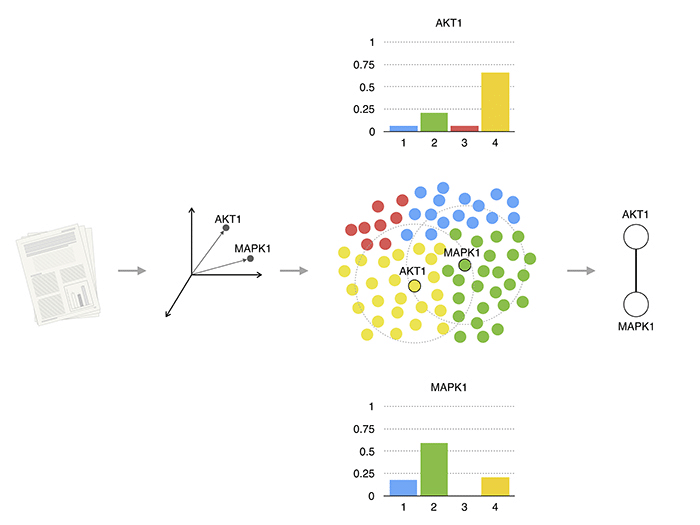
INtERAcT използва концепцията за вграждане на думи [“”word embeddings”] при обработване на текст от голямо количество биомедицински публикации. Това става възможно чрез въвеждане на нова метрика за количествено определяне на взаимодействията между протеините. Най-забележителната характеристика на технологията е, че не е необходима анотация или ръчно коригиране на текста. Тя дори може сама да прави изводи за взаимодействията в контекста на специфично заболяване.
PIMKL: Прогнозиране на развитието на болестта чрез нов ML алгоритъм
За да може лекарите да персонализират по-добре леченията на своите пациенти е нужно правилно прогнозиране на прогресията на заболяването въз основа на молекулярни данни, получени от болни тъканни проби. Макар че в миналото са предложени много машинни алгоритми, те се оказват неспособни да дадат точни прогнози. IBM обаче създава PIMKL [pathway-induced multiple kernel learning] – нов алгоритъм за машинно обучение, който може да доведе до висока прогнозна ефективност и правилна интерпретация при прогнозиране на фенотипите на базата на молекулярни данни.
Технологията прави нещата възможни чрез използване на предварително зададени знания за молекулярните взаимодействия, процеси и т.н. Използвайки техника за машинно обучение, известна като “обучение на множество ядра”, PIMKL идентифицира молекулярните пътища, които са важни за класифицирането на определените групи от пациенти. Благодарение на възможността на модела да интерпретира резултатите, новите познания за различията между групи пациенти могат да доведат до по-добро разбиране на прогресията на рака.
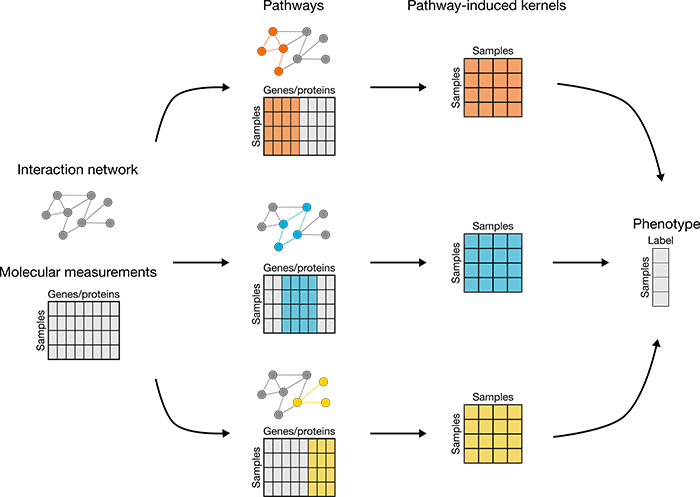
Ето какво казаха от IBM:
“В нашето проучване специално се спряхме на задачата да предвидим дали пациент с рак на гърдата ще претърпи рецидив в рамките на пет години след първото лечение. За да проверим работата на PIMKL, ние го сравнихме с 14 други подобни алгоритми, които са били прилагани по-рано към шест кохорти от рак на гърдата. PIMKL последователно превъзхожда своите партньори или се класира сред най-ефективните алгоритми за всяка отделна група.”
















